System Design
System design concepts
SYSTEM DESIGN
|
+-- FOUNDATIONS
| +-- scalability
| +-- availability
| +-- reliability
| +-- latency / throughput
| +-- CAP / PACELC
| +-- fault domains
| +-- consistency models
|
+-- ARCHITECTURE STYLES
| +-- monolith
| +-- modular monolith
| +-- microservices
| +-- SOA
| +-- event-driven systems
| +-- serverless systems
| +-- data-intensive systems
|
+-- REQUEST HANDLING
| +-- DNS
| +-- CDN
| +-- edge routing
| +-- API gateway
| +-- load balancer
| +-- reverse proxy
| +-- session handling
|
+-- COMPUTE
| +-- VMs
| +-- containers
| +-- Kubernetes
| +-- autoscaling
| +-- workers
| +-- scheduled jobs
| +-- GPU / accelerator workloads
|
+-- COMMUNICATION
| +-- REST
| +-- gRPC
| +-- GraphQL
| +-- WebSockets
| +-- Kafka
| +-- RabbitMQ
| +-- NATS
| +-- Pub/Sub
| +-- CDC
|
+-- DATA
| +-- OLTP databases
| +-- NoSQL stores
| +-- graph stores
| +-- time-series DBs
| +-- warehouses
| +-- lakes / lakehouses
| +-- search engines
| +-- vector databases
|
+-- DATA ENGINEERING
| +-- ETL / ELT
| +-- streaming
| +-- batch
| +-- enrichment
| +-- reconciliation
| +-- feature pipelines
|
+-- PERFORMANCE
| +-- caching
| +-- materialized views
| +-- partitioning
| +-- sharding
| +-- indexing
| +-- read replicas
| +-- async offloading
|
+-- RELIABILITY
| +-- retries
| +-- idempotency
| +-- circuit breakers
| +-- bulkheads
| +-- timeouts
| +-- failover
| +-- disaster recovery
| +-- multi-region design
|
+-- SECURITY
| +-- IAM
| +-- RBAC / ABAC
| +-- OAuth / OIDC
| +-- secrets mgmt
| +-- encryption
| +-- tokenization
| +-- auditability
| +-- zero trust
|
+-- OPERATIONS
| +-- metrics
| +-- logs
| +-- traces
| +-- SLOs / SLIs
| +-- alerting
| +-- on-call
| +-- runbooks
| +-- chaos testing
|
+-- AI / MODERN EXTENSIONS
| +-- model serving
| +-- RAG
| +-- vector retrieval
| +-- prompt routing
| +-- agent orchestration
| +-- evaluation pipelines
| +-- safety / guardrails
|
+-- BUSINESS TRADEOFFS
+-- cost vs performance
+-- speed vs correctness
+-- strong consistency vs availability
+-- platform standardization vs team autonomy
+-- build vs buy
1. Overview of System Design
System design refers to the process of defining the architecture, components, data flows, interfaces, and operational characteristics of large-scale software systems.
It focuses on answering questions such as:
- How should components communicate?
- How do we ensure scalability?
- How do we guarantee reliability?
- How do we design systems that evolve over time?
Modern system design must address a combination of concerns including:
- distributed computing
- scalability
- fault tolerance
- data consistency
- observability
- security
- operational resilience
Examples of systems that require sophisticated system design include:
- global social media platforms
- cloud infrastructure services
- AI platforms
- payment networks
- search engines
- real-time collaboration tools
System design is therefore a discipline that combines software engineering, distributed systems theory, networking, databases, and infrastructure engineering.
System Design Architecture Map
Below is a mind map style architecture overview.
+--------------------------------------------------------------------------------+ | 10. APPLICATION & USER INTERFACE | | Dashboards • APIs • Mobile Apps • Web Apps • Chat Interfaces | | Enterprise Integrations • Real-time UI • Notifications | +--------------------------------------------------------------------------------+ +--------------------------------------------------------------------------------+ | 9. GOVERNANCE, SECURITY & OBSERVABILITY | | Monitoring • Logging • Tracing • Alerting • Policy Engines | | Compliance • Audit Logs • Access Control | +--------------------------------------------------------------------------------+ +--------------------------------------------------------------------------------+ | 8. COMMUNICATION & DATA FLOW | | API Gateways • gRPC • REST APIs • Event Streams • Kafka | | Message Queues • Service Discovery | +--------------------------------------------------------------------------------+ +--------------------------------------------------------------------------------+ | 7. ORCHESTRATION & WORKFLOW | | Microservices Coordination • Task Scheduling | | Kubernetes • Workflow DAGs • Automation | +--------------------------------------------------------------------------------+ +--------------------------------------------------------------------------------+ | 6. APPLICATION SERVICES | | Business Logic Services • Recommendation Systems | | Payment Processing • Notification Services | +--------------------------------------------------------------------------------+ +--------------------------------------------------------------------------------+ | 5. DATA PROCESSING LAYER | | Streaming Pipelines • Batch Processing | | Data Analytics • ML Feature Pipelines | +--------------------------------------------------------------------------------+ +--------------------------------------------------------------------------------+ | 4. STORAGE & DATABASES | | Relational DBs • NoSQL • Distributed Storage | | Object Storage • Data Lakes | +--------------------------------------------------------------------------------+ +--------------------------------------------------------------------------------+ | 3. CACHE & PERFORMANCE LAYER | | Redis • Memcached • Edge Caches • CDN | +--------------------------------------------------------------------------------+ +--------------------------------------------------------------------------------+ | 2. COMPUTE INFRASTRUCTURE | | Containers • Virtual Machines • Serverless Functions | | Kubernetes Clusters | +--------------------------------------------------------------------------------+ +--------------------------------------------------------------------------------+ | 1. CLOUD / NETWORK | | Cloud Providers • Load Balancers • Networking • Storage | | Hybrid Infrastructure | +--------------------------------------------------------------------------------+
2. Fundamental Principles
2.1 Scalability
Scalability refers to the ability of a system to handle increasing workloads.
Two common scaling strategies:
Vertical scaling
Increasing the resources of a single machine.
Example: Increasing database server CPU and memory.
Horizontal scaling
Adding more machines to distribute the load.
Example: Adding more application servers behind a load balancer.
Most modern systems rely on horizontal scaling.
Example: Netflix distributes streaming workloads across thousands of servers globally.
2.2 Availability
Availability measures the percentage of time a system remains operational.
Example availability levels:
| Availability | Downtime per year |
|---|---|
| 99% | ~3.6 days |
| 99.9% | ~8.7 hours |
| 99.99% | ~52 minutes |
| 99.999% | ~5 minutes |
Example: Google Search targets extremely high availability due to global dependency.
2.3 Reliability
Reliability refers to a system's ability to function correctly even when components fail.
Strategies include:
- redundancy
- failover mechanisms
- automated recovery
Example: Amazon S3 stores multiple copies of data across availability zones.
2.4 Latency and Throughput
Latency measures response time.
Throughput measures the number of requests processed per unit time.
Example: High-frequency trading systems require microsecond latency.
3. Core Components of Distributed Systems
3.1 Load Balancers
Load balancers distribute incoming requests across multiple servers.
Examples:
- NGINX
- HAProxy
- AWS Application Load Balancer
- Google Cloud Load Balancer
Real-world example: Spotify distributes user requests across thousands of servers.
3.2 Application Servers
Application servers implement business logic.
Examples include:
- Node.js services
- Java Spring Boot services
- Python FastAPI services
In large systems, application logic is often divided into microservices.
3.3 Databases
Databases store persistent data.
Examples:
Relational databases
- PostgreSQL
- MySQL
- Oracle
NoSQL databases
- MongoDB
- Cassandra
- DynamoDB
Graph databases
- Neo4j
3.4 Caching
Caching improves performance by storing frequently accessed data in memory.
Examples:
- Redis
- Memcached
- Cloudflare edge caching
Example use case: Twitter caches timelines to reduce database load.
4. Data Storage and Management
4.1 Database Sharding
Sharding distributes data across multiple database instances.
Example: User data split across multiple servers based on user ID.
Used by:
- Uber
4.2 Replication
Replication copies data across multiple nodes.
Types:
- Master-slave replication
- Multi-master replication
Example: MySQL replication.
4.3 Eventual Consistency
Distributed systems often trade strong consistency for availability.
CAP theorem states: A distributed system can guarantee only two of the following:
- Consistency
- Availability
- Partition tolerance
Example: Amazon DynamoDB uses eventual consistency.
5. Messaging and Asynchronous Systems
5.1 Message Queues
Message queues enable asynchronous communication between services.
Examples:
- Apache Kafka
- RabbitMQ
- AWS SQS
Example: Uber uses Kafka for real-time data streaming.
5.2 Event-Driven Architectures
In event-driven systems, services react to events rather than direct requests.
Example events:
- Order created
- Payment processed
- User signed up
Example: Netflix microservices architecture.
6. Microservices Architecture
Microservices break large applications into smaller independent services.
Benefits:
- independent deployment
- improved scalability
- fault isolation
Example: Amazon's internal architecture relies heavily on microservices.
6.1 Service Discovery
Services need mechanisms to find each other.
Examples:
- Consul
- Etcd
- Kubernetes service discovery
6.2 API Gateways
API gateways manage access to backend services.
Examples:
- Kong
- AWS API Gateway
- NGINX Gateway
7. Observability and Monitoring
Modern systems must be observable to diagnose failures.
7.1 Metrics
Metrics measure system performance.
Examples:
- CPU usage
- request latency
- error rates
Tools:
- Prometheus
- Datadog
- Grafana
7.2 Logging
Logs provide detailed records of system behavior.
Examples:
- ELK Stack
- Splunk
- CloudWatch
7.3 Distributed Tracing
Tracing helps track requests across multiple services.
Tools:
- Jaeger
- Zipkin
- OpenTelemetry
Example: Debugging slow requests in microservice architectures.
8. Fault Tolerance and Resilience
Systems must tolerate failures gracefully.
8.1 Circuit Breakers
Prevent cascading failures when dependent services fail.
Example: Netflix Hystrix.
8.2 Rate Limiting
Limits traffic to protect system resources.
Examples:
- Cloudflare rate limiting
- NGINX rate limiting
8.3 Retry Mechanisms
Automatic retries help recover from transient failures.
9. Security in System Design
Security must be integrated at every layer.
Key practices include:
Authentication
- OAuth
- OpenID Connect
Authorization
- Role-based access control
Encryption
- TLS encryption for network traffic
Secrets management
- Hashicorp Vault
- AWS Secrets Manager
10. Data Pipelines and Streaming
Modern systems often process large streams of data.
Examples:
- Kafka streaming pipelines
- Spark data processing
Real-world example: LinkedIn uses Kafka for real-time analytics pipelines.
11. System Design Tradeoffs
Every system design decision involves tradeoffs.
Examples:
- Consistency vs availability
- Performance vs cost
- Simplicity vs flexibility
Example: Google Spanner prioritizes strong consistency with global distribution.
12. System Design Case Studies
12.1 Designing Twitter Timeline
Key components:
- timeline generation service
- caching layer
- distributed databases
- fan-out architecture
12.2 Designing YouTube
Components:
- video storage
- CDN distribution
- recommendation engine
- streaming servers
12.3 Designing Uber
Key services:
- location tracking
- real-time matching
- surge pricing system
13. Advanced Topics
Advanced system design topics include:
- distributed consensus (Raft, Paxos)
- service mesh architectures
- edge computing
- multi-region architectures
- AI system infrastructure
14.
15. References and Further Reading
System Design Resources
- Designing Data Intensive Applications — https://dataintensive.net/
- Google Site Reliability Engineering — https://sre.google/books/
- System Design Primer — https://github.com/donnemartin/system-design-primer
- High Scalability Blog — http://highscalability.com/
Distributed Systems
- MIT Distributed Systems Course — https://pdos.csail.mit.edu/6.824/
- Distributed Systems by Maarten van Steen — https://www.distributed-systems.net/
Observability
- OpenTelemetry — https://opentelemetry.io/
- Prometheus — https://prometheus.io/
System Design Interview Preparation
- ByteByteGo — https://bytebytego.com/
- Grokking System Design — https://www.educative.io/courses/grokking-the-system-design-interview
When I think about system design, I start from the behaviour we want at the edges: who is calling the system, what guarantees do they expect and how it should fail when things go wrong. From there, core concepts show up again and again.
- Scalability. How the system behaves as traffic or data grows: vertical vs horizontal scaling, stateless vs stateful services, sharding and partitioning.
- Latency and throughput. How quickly an individual request is served and how many we can serve per second. This drives choices like caching, batching and asynchronous processing.
- Reliability and availability. Designing for redundancy, failure domains, graceful degradation and clear SLOs (for example, availability targets or tail latency budgets).
- Consistency and durability. How quickly writes become visible and how we protect data from loss (replication, logs, checkpoints, backups).
- Data modeling. Choosing between relational, document, key-value, time-series or columnar stores and how data flows between them.
- Interfaces and contracts. Clear APIs, schemas and versioning so services can evolve independently.
- Observability and operations. Metrics, logs, traces and runbooks that make the system debuggable at 2 a.m.
- Security and compliance. Identity, access control, encryption, audit trails and data governance built into the design rather than bolted on.
- Cost and simplicity. Every design has an ongoing cost in compute, storage and human time. Simple designs that meet the requirements are usually the best ones.
Core frameworks for system design
I find it helpful to use a few simple frameworks when approaching any system design problem. They reduce anxiety and keep the conversation structured.
- Clarify, model, design, iterate. A four-step loop: (1) clarify requirements and constraints, (2) model the core data and APIs, (3) sketch a high-level architecture and (4) iterate by testing it against edge cases and growth scenarios.
- The C4 model. A way to zoom between levels of detail: context (how the system fits in the world), containers (services and databases), components (modules inside a container) and code (implementation details). C4 model site
- CAP and PACELC. CAP forces you to think about consistency, availability and partition tolerance under network failure; PACELC extends this to trade-offs between latency and consistency even when there is no partition. PACELC paper
- Reactive systems thinking. Systems that are responsive, resilient, elastic and message-driven tend to age better under load and failure. Reactive Manifesto
Example system designs
A few classic interview-style problems, but framed the way I like to think about them in real life.
1. URL shortener
A small but rich problem: map long URLs to short codes, redirect quickly and handle abuse.
- Core pieces: HTTP API, hash/id generator, key-value store, cache, background cleanup.
- Design questions: how to avoid hot keys, prevent guessing (rate limits, random IDs), and build analytics without overloading the write path.
2. News feed
Show a personalized ordered list of items (posts, alerts, tickets) to each user.
- Core pieces: write path (fan-out on write or read), feed store, ranking service, cache.
- Trade-offs: freshness vs cost, pre-computing feeds vs computing on demand, and how to roll out ranking changes safely.
3. Rate limiter and API gateway
Protect downstream services from overload and enforce product limits.
- Core pieces: edge gateways, token buckets or leaky-bucket algorithms, shared state (Redis or similar) and clear error semantics.
- Questions: per-user vs per-IP limits, soft vs hard throttling, and where to log and observe violations.
4. Log ingestion and analytics pipeline
Collect logs or events from many producers, store them reliably and make them queryable.
- Core pieces: agents/collectors, message queue (Kafka, Pulsar), long-term storage and query engines.
- Design topics: backpressure, exactly-once vs at-least-once semantics, retention policies and multi-tenant isolation.
5. Real-time chat or collaboration
Support low-latency messaging with presence and history.
- Core pieces: WebSocket or long-poll servers, message fan-out, storage for history, typing indicators and read receipts.
- Trade-offs: consistency of "read" state, ordering under failures and mobile offline behaviour.
System design for AI applications
Designing AI-powered products adds a few extra dimensions: model lifecycle, data pipelines, evaluation and safety.
- LLM-backed APIs. A stateless API layer handling authentication, billing, rate limits and routing to one or more model providers.
- Retrieval-augmented generation (RAG) services. Pipelines for document ingestion (parsing, chunking, embedding), vector stores, retrieval strategies and answer composition.
- Feature and context stores. Keeping user-specific context, preferences and history available to models while respecting privacy and data minimization.
- Evaluation, feedback and safety loops. Online and offline evaluation, red-team pipelines, human review queues and guardrails around tool use.
- Cost control. Token usage monitoring, caching, prompt reuse and routing to cheaper models for low-risk scenarios.
Many of the ideas here connect to my Agentic Architectures notes (planner–executor patterns, observability and safety) and to Psychology (how humans perceive recommendations and risk).
Here are examples of simple Agent and multi-agent Architecture designs
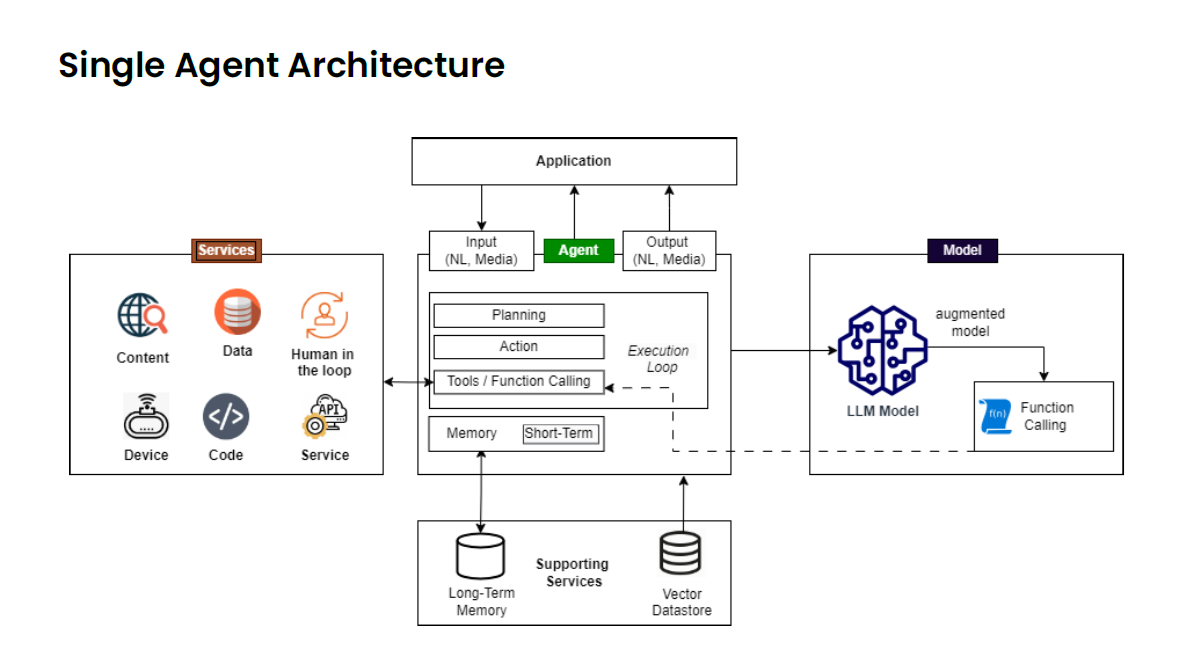
Multi-Agent Architecture
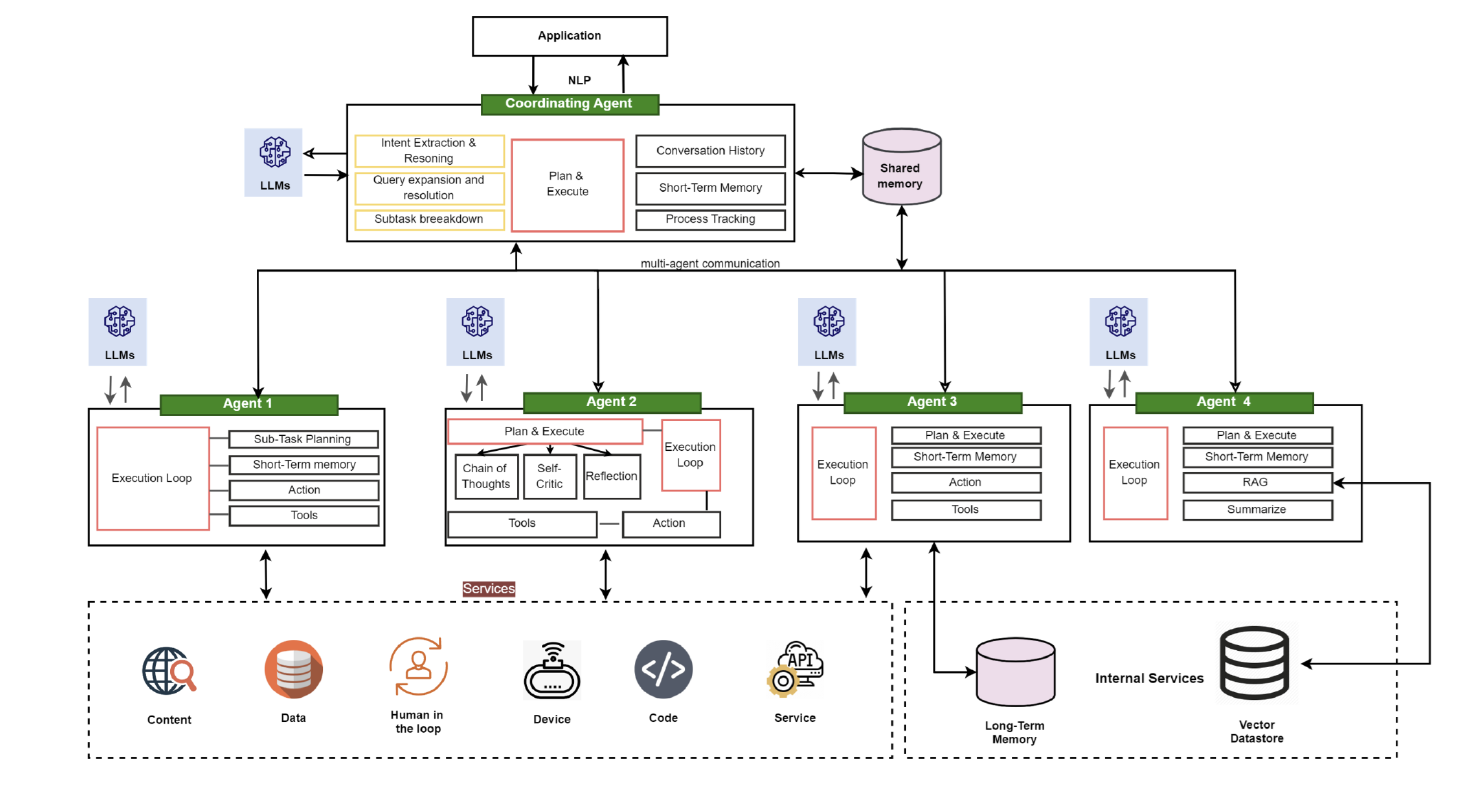
Source : https://genai.owasp.org/resource/agentic-ai-threats-and-mitigations/
Resources
Some system design resources I keep handy:
- Designing Data-Intensive Applications by Martin Kleppmann — my go-to reference for distributed data systems.
- System Design Primer — community-maintained notes and diagrams.
- ByteByteGo and YouTube channel — visual explanations of architectures.
- Gaurav Sen and other system design channels for interview-style problems.
- High Scalability — real-world architecture stories.
- The Twelve-Factor App — principles for building SaaS-style services.
- Martin Kleppmann's blog and conference talks.
Domain Experts I follow
Engineers, architects and writers whose work heavily shapes how I think about system design:
- Martin Kleppmann — distributed data systems and consistency.
- Pat Helland — essays on distributed systems and failure modes.
- Jeff Dean — large-scale systems and infrastructure at Google.
- Urs Hölzle — datacenter and infrastructure design.
- James Hamilton — datacenter engineering and reliability.
- Charity Majors — observability and operating complex systems.
- Kelsey Hightower — practical distributed systems and Kubernetes.
- Adrian Cockcroft — microservices and cloud-native architecture.
- Sam Newman — microservices patterns and boundaries.
- Werner Vogels — lessons from building and operating AWS.